
When you hit the generate button on a platform like BetterWaifu, you aren’t just searching for an image. You are watching a complex mathematical process play out in real-time. To the casual user, it looks like the AI is painting; but in reality, the AI is performing an act of sculpting.
If you want to understand how a prompt like 1girl, solo, cinematic lighting turns into a high-res illustration, you have to understand the logic of the Diffusion Model.

The Core Concept: From Chaos to Order
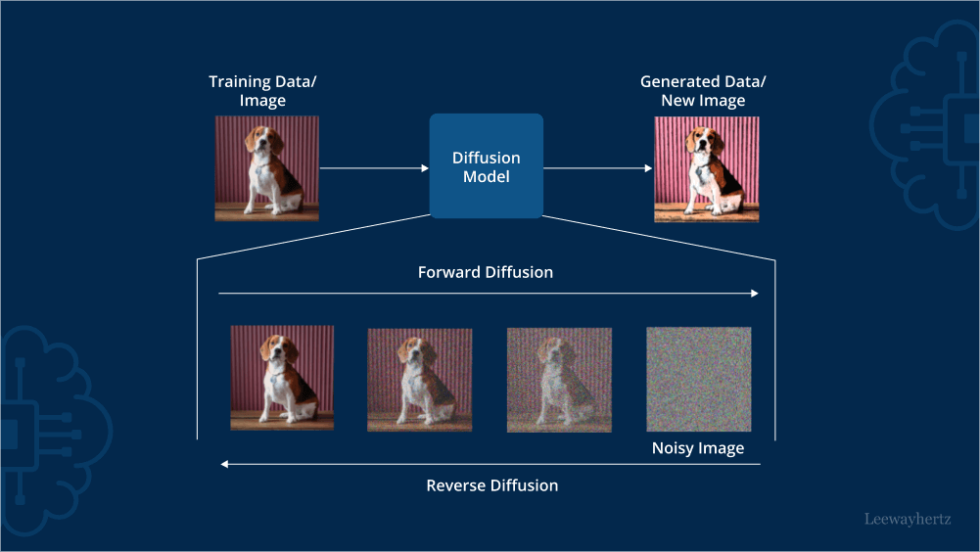
Imagine taking a high-quality anime illustration and slowly adding digital static (noise) to it. After a few steps, you can still see the character. After a hundred steps, the image is nothing but a gray, fuzzy mess of random pixels. This is called Forward Diffusion.
A hentai AI generator does the exact opposite. It starts with a canvas of pure random noise, total chaos, and is trained to perform Reverse Diffusion. It methodically denoises the static, step-by-step, until a clear image emerges.
The AI doesn’t know what a waifu is in the way a human does. Instead, it has been trained on millions of images to understand the probability of where pixels should be. If it sees a few pixels that look like the start of a sharp line, and your prompt says long hair, the AI calculates that there is a high probability that the surrounding pixels should also be part of a long, flowing line.

The Latent Secret: Working in Shorthand
One of the biggest breakthroughs in 2025 and 2026 is the use of Latent Diffusion. In the early days of AI, models tried to calculate every single pixel at once. This required a massive amount of computer power and was incredibly slow.
Modern models work in Latent Space. Think of this as a compressed version of the image. Instead of dealing with millions of individual pixels, the AI works with a mathematical shorthand that represents the essence of the image; the shapes, colors, and compositions.
Only at the very last step does a piece of software called a VAE (Variational Autoencoder) translate that mathematical shorthand back into the high-resolution pixels that we see on our screens. This is why you can generate a 4K masterpiece on a standard laptop in under thirty seconds.
The Role of the U-Net: The Brain of the Operation
While the Latent Space is the workspace, the U-Net is the brain doing the work. During the denoising process, the U-Net acts as a predictor. At every step, it looks at the current messy image and asks: “What part of this is noise, and what part is the image the user asked for?”
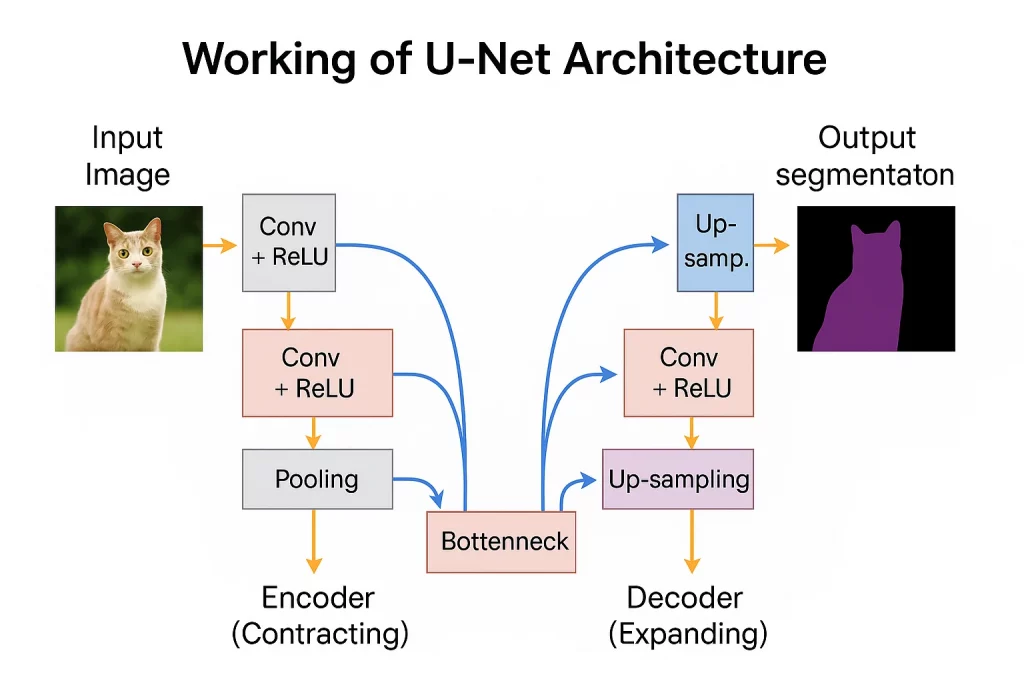
It then subtracts the noise and moves to the next step.
- Text Conditioning: This is how your prompt enters the brain. Using a system called CLIP, your text tags are turned into vectors (mathematical directions). The U-Net uses these directions to guide the denoising.
- The Guidance Factor: If you set your CFG Scale (Classifier Free Guidance) high, you are telling the U-Net to follow your text directions very strictly. If you set it low, you are giving the AI more creative freedom to interpret the noise.
Why Hentai Models Are “Smarter” Than General Ones
A general AI (like those used for stock photos) is trained on everything; dogs, cars, landscapes, and people. It’s a jack-of-all-trades but a master of none. Because it has to know so much, it often misses the subtle nuances of specific art styles.
Hentai-style diffusion models are Fine-Tuned. This means the base model (like Stable Diffusion XL) was given an extra education using a massive dataset of high-quality, uncensored anime art.
- Tag-Based Learning: Because these datasets use the “Booru” tagging system, the U-Net learns incredibly specific associations. It doesn’t just learn “eyes”; it learns the difference between tsundere eyes, blinking, and heart-shaped pupils.
- Anatomical Physics: By seeing thousands of unfiltered images, the model learns the physics of the human body; how skin reacts to pressure, how fabric drapes over curves, and how lighting interacts with different textures. This is why “safety-off” models often produce better-looking anime art even for SFW (Safe For Work) prompts; they simply have a more complete understanding of human anatomy.
Checkpoints and LoRAs: Adding Specialized Knowledge
Even within the world of hentai AI, different models have different personalities. This is due to Checkpoints. A checkpoint is the final state of the model after all that training. In 2026, models like Pony Diffusion have become the industry standard because their weights (the AI’s internal settings) have been perfectly balanced for high-res, stylized art.

Users can then add LoRAs (Low-Rank Adaptations). You can call the Checkpoint the AI’s general education and a LoRA a specialized seminar. It’s a small file that tells the U-Net how to mimic a very specific artist’s style or a specific character’s features without changing the rest of the model’s knowledge.
The Result: A New Era of Digital Artistry
When you combine the “denoising” power of the U-Net, the efficiency of “Latent Space,” and the specialized knowledge of “Hentai Checkpoints,” you get a tool that can out-paint a human artist in a fraction of the time.
But it’s important to remember that the AI isn’t thinking. It is a highly advanced statistical engine. It’s not creating in the human sense; it is finding the most likely version of your vision hidden inside a cloud of random noise. The real creator is the person providing the prompt, the negative tags, and the creative direction.
Final Thoughts: The Future of Diffusion
As we move further within 2026, the technology is only getting faster and more precise. We are seeing the rise of Real-Time Diffusion, where the image updates as you type, and Multi-Model Merging, where users can blend two different checkpoints to create an entirely new art style.
The uncensored nature of these tools is what drives this innovation. Without the restrictions of corporate safety filters, developers and users are free to push the limits of what a diffusion model can do. Whether you are a casual fan or a professional creator, understanding the “math under the hood” helps you realize that you aren’t just pushing a button, you are mastering a new form of digital sculpture.